
ABOUT MYER-BRIGGS TYPE INDICATOR
The Myers Briggs Type Indicator is a personality test that looks at an individual's psychological preferences to place them into one of 16 distinct personality types, defined by preferences spanning along four dimensions:
Extroversion-Introversion (E-I): How you interact with the world and gain energy from interactions -- by being inwardly focused (Introversion) or outwardly turned (Extroversion)?
Intuition-Sensing (N-S): How you process information -- based on the information itself (Sensing) or your own thoughts and interpretations about the information (Intuition)?
Feeling-Thinking (F-T): How you make decisions -- based on logic and hard facts in search of the objective truth (Thinking) or on personal values and an inner sense of morality in search for harmony (Feeling)?
Judging-Perceiving (J-P): How you organize your time and incoming information -- in a structured, organized way seeing the world as more black and white (Judging) or in a flexible, adaptable way preferring to keep options open (Perceiving)?
Although the MBTI has been criticized for poor reliability (i.e. producing different results when taken on different occasions by the same person) and not being entirely comprehension (due to neuroticism not being taken into account), it still remains one of the most popular online personality tests to date and is especially popular within the business sector.
The purpose of this project is to investigate whether patterns and predictive features can be extracted from the text to pinpoint an individual's personality type. The ability to use writing style and word usage to detect a person's personality might be a more precise and more reliable method of detecting pyscological preferences than self-reported tests.

LIMITATIONS WITH MBTI TESTING
There are a few issues with the current method of extracting a person's personality type. Self-reports tend to be unreliable for several reasons:
Most people can guess what personality function a question relates too (ie. We tend to be aware that the question "Do you prefer to stay in and read a book instead of going out to a party" refers to Extroversion/Introversion), and may choose to answer based on how they prefer to identify themselves as opposed to directly answering the question. This injects bias into how we choose to respond to the questions.
In many cases, we don't have a strong preference for one way or the other, or we may vary depending on our mood or other contextual information that is not present in the question. This injects unreliability in how we choose to answer and may shift results when we retake the test.
The tests improve with the addition of extra questions. However, answering so many questions may be tiring for users.
Given these limitations, using social media text might provide a more seamless and reliable method of extracting personality type. Below I will explain how I set out to achieve this.
ABOUT MBTI DATA SET
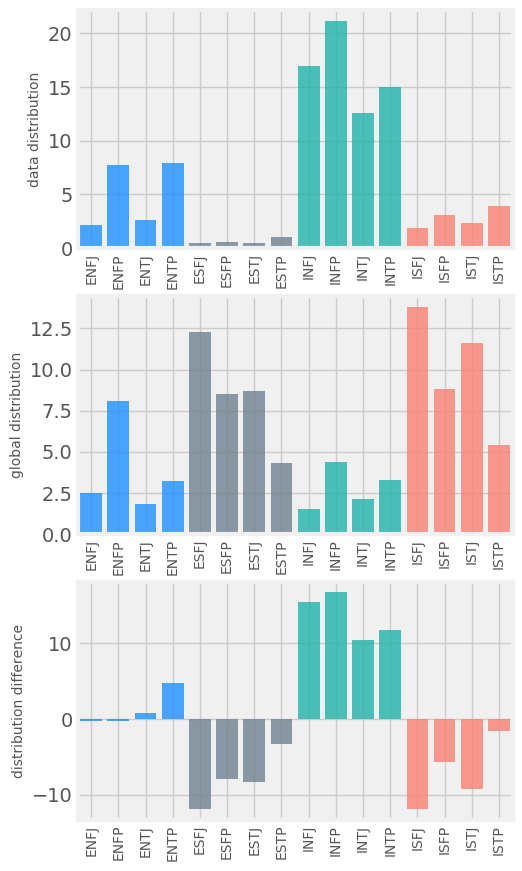
The distribution of the personality types within the data set as compared to the global distribution.
a) The distribution of the data set used. b) the global distribution. c) The distribution difference between the data set and the global distribution.
The data consisted of around ~8600 users and a combined total of 422,845 posts, gathered from personalitycafe.com (a forum used for discussing various topics pertaining to personality). Each row consisted of the users’ self-reported MBTI type and approximately 50 posts for each user in the set.
Since the data was collected from a site tailored towards a specific topic, certain words were removed that might introduce leakage into the model (i.e. if a person might be more likely to reference their own type within their posts, we don't want the model to 'cheat' by learning that 'ISFJ' is mostly linked to ISFJs).
Some words removed included Myer-Briggs types, Enneagram types, personality functions (ie Fi, Fe, Ni, Ne, etc,), and any term that may be specifically related to personality types that are not likely to be representative of the type of posts the algorithm will be used to predict off.
After doing some basic, standard cleaning of the text, the first step was looking at the distribution of the types among the data. The data set was mostly skewed towards 'IN's and 'EN's, with very few 'ES's in the set, pretty much the reverse of what the real distribution in the global population is.
Plotted above is the distribution of the types within the data set (first plot) compared to the global population distribution (second plot). The third plot shows the difference between the real percent the types appear in the world and the percent they appear in our data set. As you can see, 'IN's are vastly overrepresented in the data. 'ES's and 'IS's, by contrast, while the most common types are underrepresented within the data.
OVERSAMPLING
Given the imbalance of the data set labels, the model would be able to perform relatively well by just classifying all types as ‘IN’ types. However, this wouldn’t require the model to actually learn the differences between types and it would preform well only on a subset of personalities. We instead hope to design a model that performs well overall.
In order to account for this difference in the personality type distribution between the MBTI data set and the general global distribution, I performed SMOTE oversampling on the train set. SMOTE (Synthetic Minority Oversample Technique) is an approach to create more samples by drawing lines between real examples that are close to each other in the feature space, and randomly selecting a point along the line as a new sample. This gives us the ability to create more samples in order to create a more evenly distributed data set (and allow the model to learn better the classes that are underrepresented in the data) without just duplicating the samples that already exist, which often leads to overfitting.
Before applying the oversampling technique to the data, I decided to first explore differences and indicators of personality type that can be directly and indirectly extracted from the data.
FEATURE ENGINEERING
Particular writing styles have been found to be associated with certain personality traits. Besides just looking purely at word or topic usage, the way in which a writer expresses his or her thoughts is able to reveal character to an even stronger degree.
One example of this is how introverts have been found to use 'I', 'me', 'myself' terms more so than extroverts, who prefer 'they', 'them', 'us', 'we'. This relates to introverts' tendencies to be more inside their heads and more prone to perceiving a situation from their own viewpoint.
Other studies have found that words that are used to express balance or nuance (“except,” “but,” etc.) are correlated with higher cognitive complexity, better grades, and even truthfulness.
In addition to both of the above features being included in the featurized data set, some other features used for this task, include:
average word length
average length of post
average sentence length
sentence length variability
polarity
subjectivity
level of formality
vocabulary diversity
different parts of speech usage
frequency of using curse words
frequency of certain types of words (sad words, happy words, etc)
sentence capitalization
use of ALL CAPS
etc. ...
For the full list, view code at: github.com/rismakov/MBTI_predictor.
In addition to extracting stylistic features, I performed TFIDF on the data. (TFIDF is a measure for scoring words: in short, words that appear often in a single document, but very rarely in other documents are scored higher).
TYPE WORD USAGE DIFFERENCES
The types tend to use different types of words with more frequency. Doing a TFIDF analysis, which observes how often a word is used in a specific text normalized to the times it's used in general among all the texts available, I investigated which words were used most often by which type.
Plotted below are the top TFIDF words used by each type as compared to all the rest of the types. As you can see, 'INF' types tend to use words like 'dreams', 'heart', 'soul', 'sad', while 'INT' and 'ENT' types tend to use 'argument', 'debate', 'science', 'intelligence', as well as higher levels of swear words. 'ES' and 'IS' types tend to use words more often pertaining to physical objects and people: 'husband', 'sister', 'coffee', 'phone', etc.

The top 15 highest TFIDF words that appear for each personality type.
TYPE WRITING STYLE DIFFERENCES




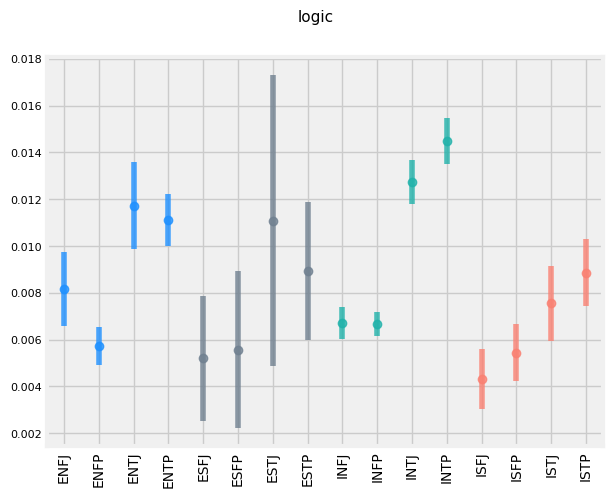

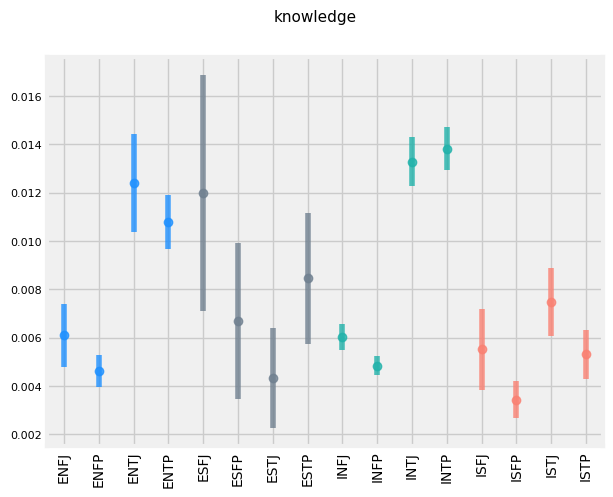
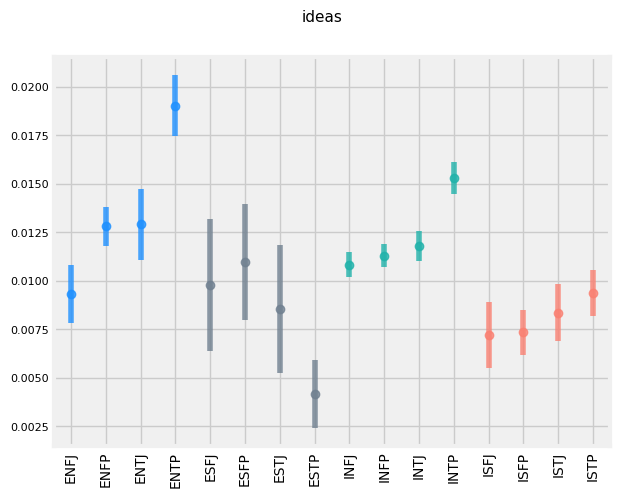

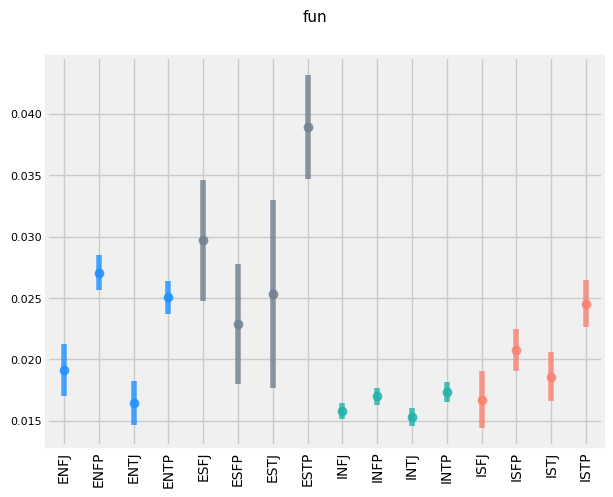
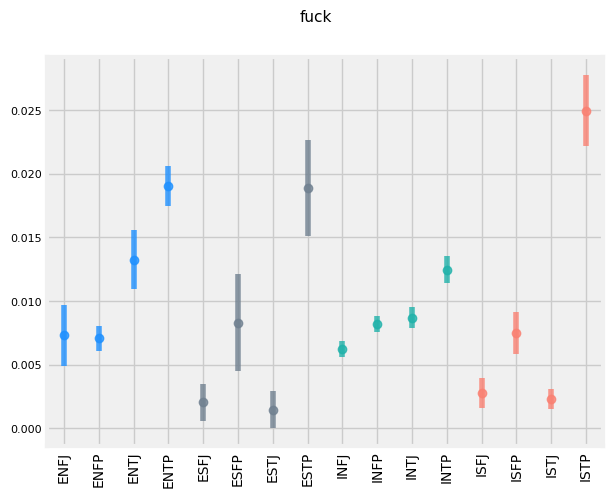
FUNCTIONS WRITING STYLE DIFFERENCES
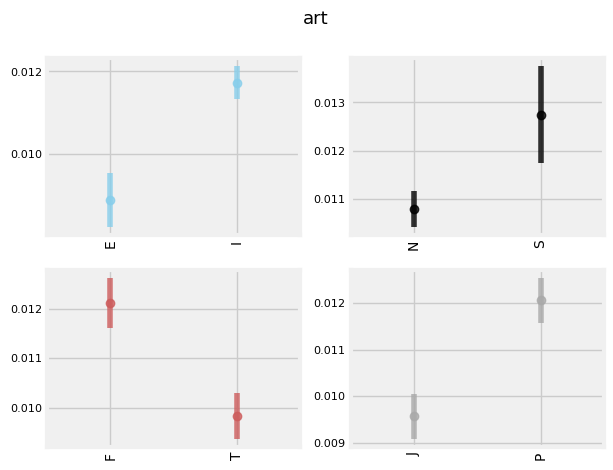





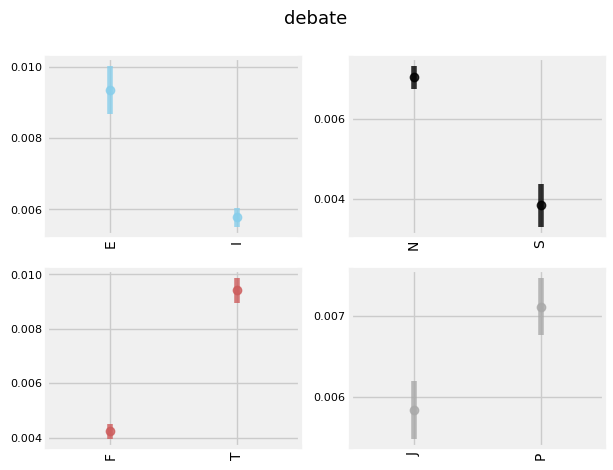
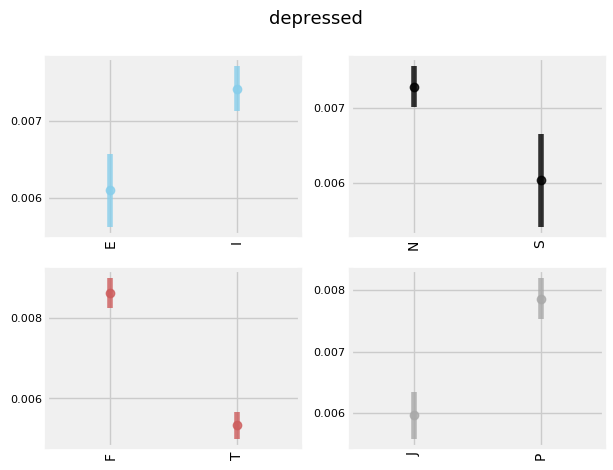



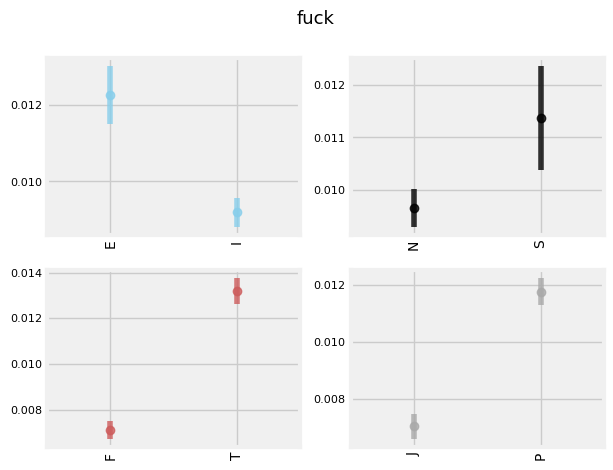
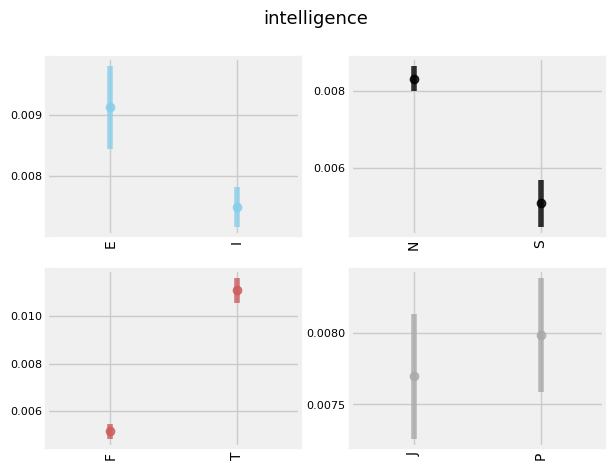




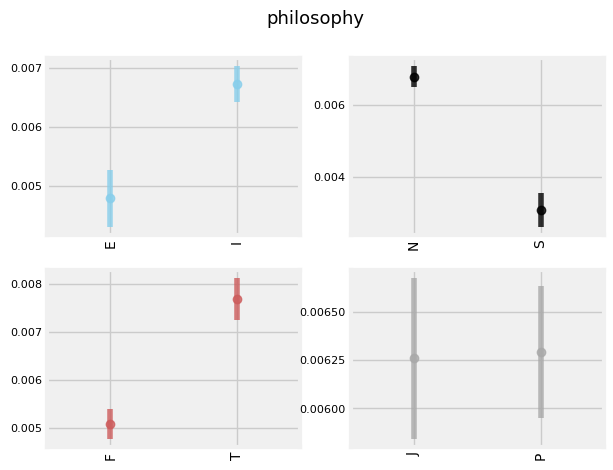

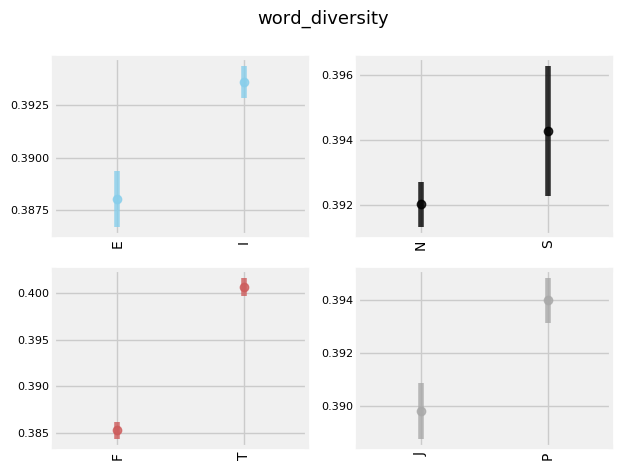
INTERESTING TRENDS
It appears that the use of 'Mom' and 'Mother' is inversely related. 'E', 'S', 'F', and 'P's tend to use 'Mom' more frequently, while 'I', 'N', 'T', and 'J's tend to use 'Mother'.
'E', 'N', 'T', and 'P's tend to use the term 'debate' more frequently (given that ENTPs are known as 'the debaters', this makes sense.)
'E', 'S', 'T', and 'P's tend to use the word 'drunk' more frequently. This makes sense for extroverts (who prefer partying compared to introverts), sensors (who prefer the concrete and physical compared the intuitives), and perceivers (who are more in the moment than their Judging counterpoints). Why Thinkers are more likely to be getting drunk than Feelers is less intuitive, however.
It appears that 'NF's are more likely to use both the words 'happy' and 'sad' than 'NT's are, showing that they tend to focus more on emotions in general.
There appears to be a trend of TP > TJ > FP > FJ for use of the word 'math' for Intuitive types.
Thinkers appear to use the word 'debate' more so than Feelers for Intuitive types.
'E', 'N', 'F', and 'P's tend to display more subjectivity in their posts.
'N', 'T', and 'J's tend to capitalize their sentences more frequently.
'I', 'T', and 'P's tend to shower a higher level of diversity of vocabulary in their text.
'I', 'S', 'T', 'P's also tend to swear more frequently.
Note: given that there were so few 'ES' types, it was more difficult to pick out trends within this group.
To see more trends and compare word usage and stylistic differences between personality types and between function types, you can run the 'plotting.py' functions available on GitHub.
WEB APP
To explore how the algorithm makes its predictions, you can play around with the Web App here: MBTI Prediction Web App